参考书籍:
《HeadFirst 设计模式》
《设计模式-可复用面向对象软件的基础》
本文主要介绍对象行为型模式——Observer(观察者)模式,介绍的内容基于HeadFirst设计模式这本书,由于这本书是通过java编写,学习C++的朋友可能有所疑惑,因此本文借助GoF将其例子通过C++进行改编。
简介
观察者模式定义了对象间一对多的依赖关系,当一个对象(本文称其为目标对象)的状态发生改变时,所有依赖它的对象(本文称其为观察者对象)都会得到通知并被自动更新。
more >>参考书籍:
《HeadFirst 设计模式》
《设计模式-可复用面向对象软件的基础》
本文主要介绍对象行为型模式——Observer(观察者)模式,介绍的内容基于HeadFirst设计模式这本书,由于这本书是通过java编写,学习C++的朋友可能有所疑惑,因此本文借助GoF将其例子通过C++进行改编。
观察者模式定义了对象间一对多的依赖关系,当一个对象(本文称其为目标对象)的状态发生改变时,所有依赖它的对象(本文称其为观察者对象)都会得到通知并被自动更新。
more >>套接字是通信端点的抽象,和文件描述符类似,程序通过套接字描述符访问套接字。事实上,套接字在UNIX中就是一种文件描述符,许多处理文件描述符的函数(如read、write)也可以用于处理套接字。
socket函数创建一个套接字。
1 |
|
参数domain(域)描述了通行的特性,有以下取值:
参数type确定套接字类型,POSIX.1定义了以下套接字类型:
SOCK_STREAM提供字节流服务,应用程序分辨不出报文界限,从该套接字读取数据时,不会返回发送进程的所有字节数,需要多次函数调用才能获得所有数据。
SOCK_SEQPACKET提供基于报文服务,从该套接字获取的数据量与发送方一致。SCTP提供因特网域上的顺序数据包服务。
SOCK_RAW提供数据报接口,直接访问下层网络层(即IP层),应用程序自己负责构造协议头部。
参数protocol通常为0,表示给定的域和套接字类型选择默认协议。AF_INET中,type为SOCK_STREAM默认协议为TCP;AF_INET中,type为SOCK_DGRAM默认协议为UDP。
调用close可以关闭对套接字的访问,释放该套接字以重新使用。
函数shutdown可以禁止一个套接字的I/O
1 |
|
参数how为SHUT_RD,表示关闭读端,无法从套接字读取数据;若为SHUT_WR,表示关闭写端,无法向套接字发送数据;若为SHUT_RDWR,表示即无法读取数据,也无法发送数据。
进程标识用于标志一个通行目标进程,由两部分组成:一部分为计算机的网络地址,标识了想要通信的计算机;另一部分为端口号,标识了特定的进程。
与不同计算机的进程通信,需要考虑字节序,字节序有大端法和小端法。Linux、FreeBSD、MAC OS为小端法,Solaris为大端法。
网络协议指定了字节序,因此计算机通信时不会被字节序混淆。TCP/IP协议为大端字节序。
对于TCP/IP应用程序,有4个函数用于主机字节序与网络字节序之间的转换。
1 |
|
h表示主机,n表示网络,l表示长(4字节)整数、s表示短(2字节)整数。
为使不同地址能够传入套接字函数,地址会被强制转换成一个通用地址结构sockaddr:
1 | struct sockaddr { |
套接字实现可以自由添加额外成员。
在IPv4因特网域(AF_INET)中,套接字结构为sockaddr_in:
1 | struct in_addr { |
IPv6因特网域(AF_INET6)套接字结构为sockaddr_in6:
1 | struct in6_addr { |
尽管sockaddr_in和sockaddr_in6结构相差较大,但它们均被强制转换成sockaddr结构输入套接字程序中。
函数inet_ntop和inet_pton用于二进制地址格式和点分十进制表示(a.b.c.d)之间的转换,并且同时支持IPv4和IPv6。
1 |
|
inet_ntop将网络字节序的二进制地址转换成文本字符串格式,inet_pton将文本字符串格式转换成网络字节序的二进制地址。
参数domain只支持AF_INET和AF_INET6。
参数size指定了保存文本字符串的str的大小,INET_ADDRSTRLEN定义了足够存放IPv4的大小,INET6_ADDRSTRLEN定义了足够存放IPv6的大小。
管道具有两个局限性:
管道通过调用pipe函数创建。
1 |
|
参数fd返回两个文件描述符:fd[0]负责读、fd[1]负责写。fd[1]的输出是fd[0]的输入。对于支持全双工管道的系统,fd[0]和fd[1]以读/写方式打开。
一般来讲,使用管道通常进程会调用pipe,然后调用fork,从而创建从父进程到子进程的IPC通道,如下图所示:
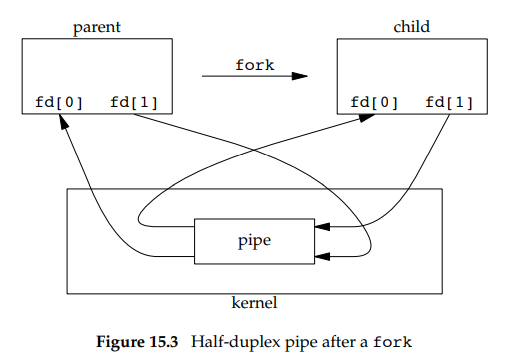
之后如果想创建从父进程和子进程的管道,父进程可以关闭读端(fd[0]),子进程关闭写端(fd[2])。如下图所示:
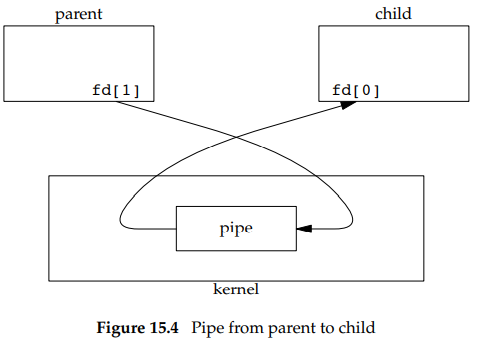
当管道一端被关闭时,会有以下规则:
下面创建了一个从父进程到子进程的管道,并父进程从管道中向子进程传送数据。
1 |
|
标准I/O库提供了两个函数popen和pclose,这两个函数的操作是:创建一个管道,fork一个子进程,关闭未使用的管道端,执行shell命令,然后等待命令终止。
1 |
|
函数popen先执行fork,然后调用exec执行cmdstring,并返回一个文件指针。若type是“r“,则文件指针连接到cmdstring的标准输出,表示进程可以从管道里读数据;若type是”w”,则文件指针连接到cmdstring的标准输入,表示进程可以向管道里写数据,如下所示:
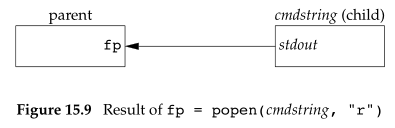
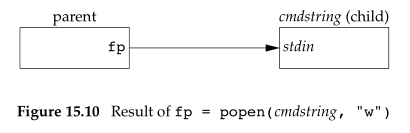
函数pclose关闭标准I/O流,等待命令终止,然后返回shell的终止状态。
popen和pclose的具体实现:
1 |
|
UNIX系统过滤程序从标准输入读取数据,向标准输出写数据,几个过滤程序在shell管道中线性连接。当一个过滤程序既产生某个过滤程序的输入,又读取该过滤程序的输出,则它就是协同进程。
popen只提供连接到另一个进程的标准输入或标准输出的一个单项管道,而协同进程有连接到另一个进程的两个单项管道:一个连接到标准输入、一个连接到标准输出。可以将数据写到标准输入,经过处理后,在从其标准输出读取数据。示意图如下图所示:
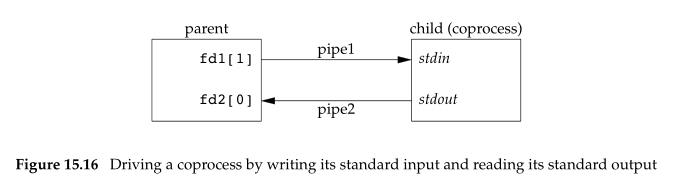
下面是一个简单的协同进程示例,协同进程从其标准输入读取两个数,计算它们的和,然后输出到标准输出。
1 |
|
FIFO又称命名管道,匿名管道只能在只能用于有相同父进程的两个进程通信。而通过FIFO,不相关的进程也能交换数据。
FIFO是一种文件类型,通过stat结构的st_mode字段可以直到文件是否是FIFO。创建FIFO类似于创建文件:
1 |
|
当用mkfifo或mkfifoat创建FIFO使,要用open打开它。正常的文件I/O函数都需要FIFO。
当open一个FIFO是,非阻塞标志(O_NONBLOCK)会有一下影响:
类似于管道,若write一个没有读进程的FIFO,则产生信号SIGPIPE。若FIFO的最后一个写进程关闭了FIFO,则为该FIFO产生一个文件结束标志。
一个给定的FIFO有多个写进程是常见的,如果要保证数据不交叉,则需要保证写操作的原子性。和管道一样,PIPE_BUF是原子地写入FIFO的最大数据量。
有三种称为XSI IPC的IPC:消息队列、信号量、共享内存。
每个IPC结构关联一个ipc_perm结构,该结构定义了权限和所有者,至少包括:
1 | struct ipc_perm { |
修改这些值,调用进程必须是IPC结构的创建者或者超级用户。
mode字段表示权限,任何IPC不存在执行权限,消息队列和共享内存使用术语“读”和“写”,信号量使用“读”和“更改”,下表是每种IPC的权限。
| 权限 | 位 |
|---|---|
| 用户读 | 0400 |
| 用户写(更改) | 0200 |
| 组读 | 0040 |
| 组写(更改) | 0020 |
| 其他读 | 0004 |
| 其他写(更改) | 0002 |
消息队列是消息的链接表,存储在内核中,有消息队列标识符标识。
msgget用于创建新队列或打开一个现有队列;msgsnd将消息添加到队列尾部;msgrcv用于从队列中取消息。消息并不一定要以先进先出的次序取,也可以按照消息的类型取消息。
每个队列都有一个msqid_ds结构与其关联:
1 | struct msqid_ds { |
此结构定义了队列的当前状态。
调用的第一个函数通常是msgget,其功能是打开一个现有队列或创建一个新队列:
1 |
|
参数key讨论了是创建一个新队列还是引用现有队列。在创建新队列时,需要初始化msqid_ds结构的下列成员:
若执行成功,msgget返回非负队列ID。该ID可用于后续的消息队列函数。
函数msgctl可以对队列执行多种操作。
1 |
|
参数cmd指定了msqid指定队列要执行的命令,有:
函数msgsnd将数据放进消息队列中。
1 |
|
每个消息由3部分组成:正的长整型字段、非负的长度、实际数据字节数。并且消息总是放在队列尾端。
参数ptr指向一个长整型数,包括整型消息类型,紧接着是消息数据(若nbyte为0,则无消息数据)。若发送的最长消息为512字节,因此可以定义以下结构:
1 | struct mymesg { |
ptr就可以是指向mymesg结构的指针。接受者可以通过消息类型以非先进先出的次序取消息。
参数flag可以指定为IPC_NOWAIT。这类似于I/O中的非阻塞I/O标志,若消息已满,则指定了IPC_NOWAIT的msgsnd操作会立即出错并返回EAGAIN。如果没有指定IPC_NOWAIT,则进程会一直阻塞,直到1)有空间容纳消息;2)或系统删除该消息队列,返回EIDRM错误;3)或捕捉到一个信号,并从信号处理函数返回,返回EINTR错误。
当msgsnd成功返回时,消息队列的msqid_ds结构会更新,表明调用的进程ID(msg_lspid)、调用时间(msg_stime)、新增消息(msg_qnum)。
函数msgrcv从消息队列中取消息。
1 |
|
参数ptr与msgsnd类似,包括消息类型和消息数据缓冲区;nbytes指定缓冲区长度,若返回消息的长度大于nbytes,如果flag设置MSG_NOERROR位,则将该消息截断,如果没有设置该位,则函数出错返回E2BIG(消息仍在队列中)。
参数type有三种情况:
参数flag可指定为IPC_NOWAIT,这样,若无指定类型的消息,则msgrcv返回-1,error设置为ENOMSG。如果没有设置IPC_NOWAIT,则进程阻塞,直到1)有指定类型消息可用、2)或系统删除此队列(返回-1,error设置为EIDRM)、3)或捕捉到一个信号并从信号处理函数返回(返回-1,error设置为EINTR)。
msgrcv成功执行时,内核更新该消息队列相关的msgid_ds结构,有指示调用者的进程ID(msg_lrpid)、调用时间(msg_rtime)、指示消息数减少1(msg_qnum)。
因为:
该IPC没有引用计数,当向队列中添加消息后直接终止,该消息队列不会被删除,直到进程调用msgrcv或msgctl或删除该消息队列。直到最后一个引用FIFO的进程结束,FIFO名字仍保留在系统中;
该IPC不使用文件描述符,因此无法使用I/O多路复用函数(select、poll),这使得很难一次使用一个以上的IPC结构。
目前为止,在速度上管道和FIFO相差无几,因此,在新的程序中不应该使用FIFO。
信号量与前面的IPC不同,它是一个计数器,用于为多个进程提供对共享数据对象的访问。
为了获得共享资源,进程需要:
常用的信号量为二元信号量,它控制单个资源,初始值为1。但是信号量初值可以是任意初值,表示控制了多少个共享资源单位。
内核为每个信号量集合维护一个semid_ds结构:
1 | struct semid_ds { |
每个信号量由一个无名结构表示,它至少包括:
1 | struct { |
要想使用信号量,首先需要调用semget函数获得一个信号量ID。
1 |
|
创建一个新集合时,要对semid_ds结构的下列成员赋值:
nsems是该集合中的信号量数。
函数semctl包含了多个信号量操作
1 |
|
第4个参数可选,若使用,则类型是semun,如下:
1 | union semun { |
注意这里是union,不是指向union的指针。
参数cmd有以下命令:
除GETALL以外的所有GET命令,semctl返回相应的值。其他命令,若成功,返回0;如出错,返回-1,并设置errno。
函数semop自动执行信号量集合上的操作数组。
1 |
|
semoparray是一系列信号量操作的数组:
1 | struct sembuf { |
参数nops指定了该数组中操作的数量。
semop具有原子性,对数组中的操作,它或者执行所有操作,或者一个不做。
注意,对于多个进程间共享一个资源,对单一资源加锁,我们应该使用记录锁,因为它比信号量更简单、速度更快,并且系统会管理进程结束后遗留下的锁(对于信号量要指定SEM_UNDO标志)。
共享存储允许多个进程共享给定的存储区,因为数据不需要拷贝,因此是最快的IPC。使用共享存储时,需要同步多个进程,例如在服务进程正在写数据,那么客户进程不应该读数据。通常,信号量用于同步共享存储的访问。
XSI共享存储与内存映射文件的区别是,前者没有相关的文件,且共享存储段是内存匿名段。
内核为每个共享存储段维护一个结构,该结构至少有:
1 | struct shmid_ds { |
shmget通常是第一个调用的函数,它获得一个共享存储标识符
1 |
|
key用于表示是创建一个新共享存储段,还是引用一个现有的共享存储段。当创建一个新段时,需要初始化shmid_ds结构的以下成员(和消息队列、信号量类似):
参数size是共享存储段的长度,以字节为单位。通常为向上取整的系统页长(Linux是4096字节)的整数倍。当创建段时,指定size大小,当引用段时,size为0。
和消息队列、信号量类似,shmctl函数对共享存储段执行多种操作。
1 |
|
cmd参数指定5中命令:
创建了一个共享存储段后,进程可以通过函数shmat将其映射到它的地址空间中。
1 |
|
对于参数addr,表示共享存储映射到进程的地址,除非只计划在一个硬件上允许,否则不应该设置该值,应当指定addr为0,由内核决定地址。
参数flag如果为SHM_RDONLY,表示只读该共享存储段,否则为读写方式连接此段。
函数shmdt可以将进程与该段分离,注意,此时并没有删除其标识符和相关数据结构。标识符会一直存在,直到有进程使用IPC_RMID的调用shmctl函数删除它为止。
1 |
|
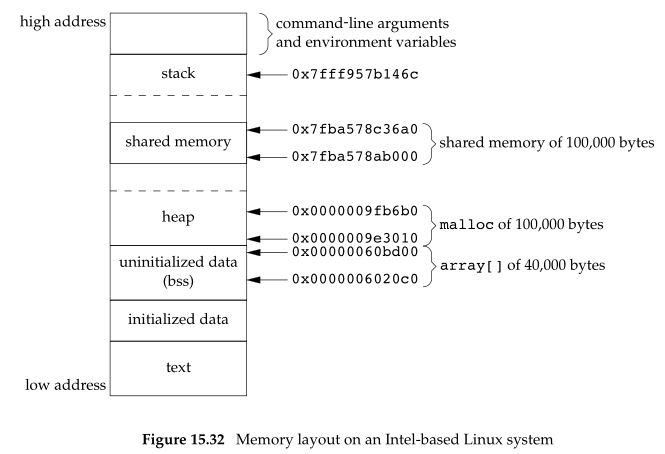
下面的程序是测试存储区各个段(bss段、堆段、栈段、data段)和共享存储段的空间分布位置。
1 |
|
在我的Linux中,其输出如下:
array[] form 0x555e5adf8060 to 0x555e5adf9000
stack around 0x7fff0cbb73a4
malloced from 0x555e5ca946b0 to 0x555e5caacd50
shared memory attached from 0x7f150fdd7000 to 0x7f150fdef6a0
可以看到,它与典型存储区分布类似:
POSIX信号量相较于XSI信号量有了优化,解决了XSI信号量的缺点:
POSIX信号量有两种形式:命名的和未命名的。它们的差异在创建和销毁上,其他工作一样。
未命名信号量只存在内存中,要求使用信号量的进程必须可以访问该内存(也就是信号量所在内存位置),因此它只用于:(1)同一进程的线程;(2)不同进程将信号量所在内存映射到各自空间中的线程。
命令信号量可以通过名字访问,可以被任何一直它名字的进程使用。
函数sem_open可以创建一个新的命名信号量或使用一个现有信号量。
1 |
|
参数name是信号量的名字;
参数oflag指定函数动作标志,oflag如果是O_CREAT,则表示创建信号量,若信号量存在,则无额外的初始化发生,并且函数不会出错;若确保要创建信号量,则oflag设置诶O_CREAT|O_EXCL,此时如果信号量已存在,sem_open会调用失败。
另外两个参数用于创建信号量,mode指示信号量权限,value指示信号量的初始值。
函数sem_close用于释放任何与信号量相关的资源。
1 |
|
如果进程没有调用sem_close后退出,则内核会自动关闭任何打开的信号量。
函数sem_unlink用于销毁一个命名信号量
1 |
|
如果name指示的信号量没有被引用,则该信号量被销毁;若有引用,则销毁会延迟到最后一个引用关闭。
函数sem_wait或sem_trywait用于信号量减1操作。
1 |
|
调用sem_wait函数在信号量为0时,进程会进入阻塞状态,而调用sem_trywait函数在信号量为0时,则直接出错返回-1,并将errno置为EAGAIN。
函数sem_timewait可以设定阻塞时间
1 |
|
如果超时信号量没能减1,则返回-1,并将errno设置为ETIMEOUT。
函数sem_post可使信号量加1,若调用sem_post时,有进程因为sem_wait阻塞,则进程被唤醒,并信号量被sem_wait减1。
1 |
|
若只想在单个进程中使用POSIX信号量,使用未命名信号量更容易。函数sem_init创建一个未命名信号量。
1 |
|
pshared参数表示是否要在多个进程中使用信号量,如果是,则设置其为非0。value指定信号量的初始值。
sem参数则是一个声明的sem_t类型变量的地址,而不需要通过sem_open。
未命名信号量使用完成后,调用sem_destroy丢弃它。
1 |
|
函数sem_getvalue可以检索信号量值。
1 |
|
成功后,valp指向的整数就是信号量值。注意,在获取到信号量值后,该值有可能已经改变,除非使用额外的同步机制避免竞争,否则该函数只适用于调试。
下面通过信号量来实现互斥锁,该锁能被一个线程加锁而被另外一个线程解锁,它的结构可以是:
1 | struct slock { |
下面是通过信号量实现互斥原语。
1 | /* 头文件 */ |
这一章介绍了进程间通信的方式:管道、命名管道(FIFO)、通常称为XSI IPC的3种形式的IPC(消息队列、信号量、共享存储)、POSIX提供的替代XSI IPC信号量的机制。
APUE上给出的建议是:学会使用管道和FIFO,这两种IPC技术可以有效应用于大量程序。在新程序中,避免使用消息队列及信号量,应当考虑全双工管道和记录锁代替,因为它们使用更简单。共享存储仍有它的用途,虽然mmap(存储映射I/O的函数)有同样的效果。
本章主要讨论的是高级I/O话题,有:非阻塞I/O、记录锁、I/O多路转接、异步I/O、存储映射I/O等。
系统调用可以分为:”低速“系统调用和其他,低速系统调用是指可能会使进程永远阻塞的系统调用,对于像读写磁盘文件的I/O会暂时阻塞调用者,不能称为低速I/O。
非阻塞I/O可以在我们使用open、read、write等I/O操作时,保证这些操作不会阻塞。如果该操作不能完成,调用会立即出错并返回,表示该操作如果继续就会阻塞。
下面是使用非阻塞I/O的实例,它从标准输入中读取500000字节,然后试图将它们写到标准输出上,它将标准输出设置为非阻塞
1 |
|
这里使用while循环的方式进行调用write函数,该方式称为轮询,若标准输出是终端时(因为终端是行缓冲,超过缓冲上限,缓冲会被冲洗,冲洗时write调用就会失败),会反复调用write系统调用,并且大多数会返回错误,这会浪费CPU的时间,后续会讲到可以使用I/O多路转接,很好的解决这类问题。
记录所(record locking,又称字节范围锁)的功能是:当一个进程正在读或写文件的某个部分时,记录锁可以阻止其他进程修改同一文件区。注意,这里是锁住文件区域,可以是一个文件,也可以是一个文件中的一个字节。
在Linux中可以使用fcntl方法设置记录锁。
1 |
|
对于记录锁,cmd是F_GETLK、F_SETLK、F_SETLKW,第三个参数是指向flock结构的指针:
1 | struct flock { |
由l_type可知,记录锁的效果和线程中的读写锁效果类似,读锁共享,写锁独占。
若一个进程在同一个文件区两次加锁,则新锁会替换旧锁。
fcntl的cmd参数可以有下面3个(记录锁情况下):
注意,若想使用F_GETLK测试是否可以获取锁,然后用F_SETLK或F_SETLKW获取锁,这两者之间不是原子操作,不能保证在两个操作之间没有其他进程企图获取相同的锁。
如果两个进程相互等待对方持有并且不释放锁定的资源时,则两个进程就会处于死锁状态。下面是死锁的例子,子进程对第0字节加锁,父进程对第1字节加锁,并且它们试图向对方加锁的字节加锁。我在原书的基础上添加了一些打印动作,以便直观的看到父进程和子进程的动作。
1 |
|
下面是上述自定义函数的实现,也添加的一些打印动作:
1 |
|
在linux中,上述的程序输出为:
parent: got the lock, byte 1
父进程发送信号SIGUSR1
父进程进入休眠
child: got the lock, byte 0
子进程发送信号SIGUSR2
子进程进入休眠
子进程解除休眠
子进程尝试获取字节1
父进程解除休眠
父进程尝试获取字节0
parent: writew_lock error: Resource deadlock avoided
child: got the lock, byte 1
检查到死锁时,内核必须选择一个进程接受出错返回,这里内核决定的是父进程出错返回,子进程成功获取父进程控制的字节。
记录锁的自动继承和释放有3条规则:
锁与进程和文件两者关联,这里有两重含义:(1)当一个进程终止,其建立的锁全部释放;(2)一个文件描述符关闭时,进程通过该文件描述符引用的文件上的锁都会被释放。如下:
1 | fd1 = open(pathname, ...); |
在执行close(fd2)后,通过fd1创建的锁也会被释放,因为fd2和fd1指向同一个文件
文件尾端会一直变化,因此在向文件尾端加锁或解锁时需要小心。考虑下面代码:
1 | writew_lock(fd, 0, SEEK_END, 0); //自定义函数,功能是:向文件尾端添加写锁 |
在文件尾端添加写锁,后续向文件写的任何数据也会被锁上。上述代码的效果如下:
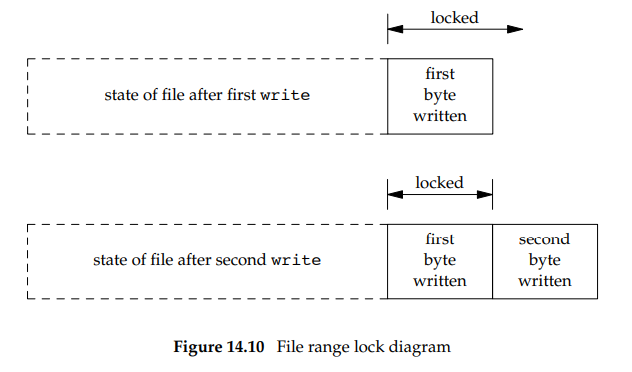
如果想要解除包括第一次write所写字节的锁,则在un_lock函数中的第二个参数设置为-1,表示解锁的区域从当前位置(这里是文件末尾)的上一个字节开始,这样就可以释放所有锁了。
当从一个文件描述符读,然后写到另一个文件描述符,可以使用下述的阻塞I/O:
1 | while ((n = read(STDIN_FILENO, buf, BUFSIZ)) > 0) |
但是,如果必须从两个文件描述符读,就不能使用这种阻塞I/O了,因为我们不能在一个描述符上阻塞read,如果此时另一个文件描述符有数据,就无法调用read进行处理,例如:
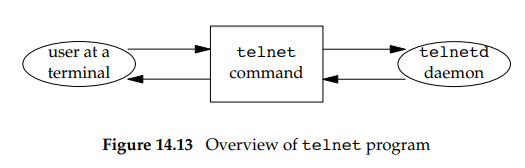
telnet程序有两个输入,两个输出。因为不知道是哪一个输入会有数据,不能对两个输入的任何一个进行阻塞。
解决这个问题较好的技术是I/O多路转接。先构造一个描述符列表,然后调用一个函数,直到这些描述符中的一个已经准备好I/O时,函数才返回。poll、pselect、select这3个函数可以执行I/O多路转接。
通过select参数可以告诉内核:
select返回后,内核告诉我们:
根据select返回的信息,就可以调用相应的I/O函数,并且保证该函数不会阻塞。
1 |
|
对于参数tvptr有三种情况:
中间三个参数readfds、writefds、execptfds是指向描述符集的指针,每个描述符集存储在fd_set结构中,可以认为它是一个很大的数组。
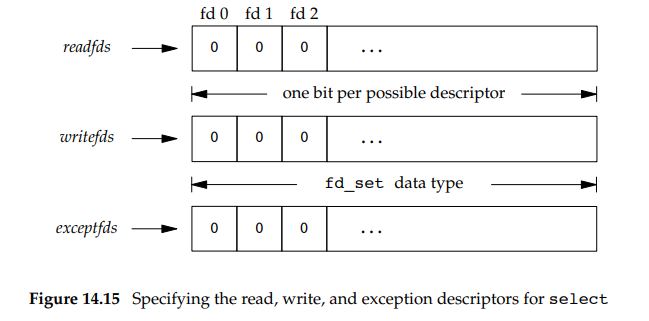
参数maxfdp1表示”最大文件描述符编号值加1“。通过我们给定最大描述符,则内核只需要在此范围内寻找即可,而不需要在没有使用的位内搜索。
select函数有三种返回值:
pselect是select的变体,它可以安装信号屏蔽字。
1 |
|
pselect和select有以下不同:
poll类似select,但接口不同:
1 |
|
与select不同,poll通过pollfd数组,每个数组元素指定一个描述符编号和对描述符感兴趣的条件。
1 | struct pollfd { |
fdarry数组中元素个数由nfds指定。pollfd中的events告诉内核我们关心的描述符对应的事件。返回时,内核设置revents,说明对应描述符发生的事件。(注意,poll没有修改events成员)。
poll中的timeout表示我们愿意等待的时间。如同select,有3个情形:
与select相同,一个文件描述符阻塞并不影响poll阻塞。
异步I/O使用一个信号(System V中是SIGPOLL,BSD中是SIGIO)通知进程,表示某个描述符关心的时间已经发生。但信号只有一个,当如果有多个描述符使用异步I/O,进程接收到该信号时不知道其对应的是哪一个文件描述。
异步I/O接口使用AIO控制块来描述I/O操作,aiocb结构描述了AIO控制块,至少包括一下字段:
1 | struct aiocb { |
异步I/O接口的偏移量并不影响操作系统维护的文件偏移量。只要在一个进程中,不将异步I/O函数和传统I/O函数(指read、write)一起使用,就不会出问题。
aio_sigevent字段结构如下:
1 | struct sigevent { |
sigve_notify字段控制通知的类型,取值有3种:
函数aio_read进行异步读操作,函数aio_write进行异步写操作。
1 |
|
当函数返回成功时,异步I/O请求被操作系统放入等待队列中。注意,两个函数的返回值与I/O操作无任何关系,在I/O完成之前,AIO控制块和缓冲区不能被复用。
函数aio_fsync可以强制所有等待中的异步操作立即执行写入持久化存储过程,也就是执行数据同步操作。
1 |
|
在异步同步操作完成前,数据不会被持久化。
函数aio_error可以获取异步读、写、同步操作的完成状态。
1 |
|
aio_error有返回值有四种情况:
异步操作成功后,可以调用aio_return获取异步操作返回值
1 |
|
aio_return的返回值
注意,在异步操作完成之前,不要调用aio_return,此时操作未定义;并且对一个异步操作只能调用一次aio_return。调用该函数后,操作系统会删除I/O操作的返回值。
执行I/O操作时,不想被阻塞就可以使用异步I/O。当所有事务都完成,还有异步操作没有完成,则可以调用aio_suspend阻塞进程,直到异步操作完成。
1 |
|
如果调用aio_suspend的阻塞过程中,被信号中断,则它返回-1,并在errno中设置EINTR;
如果没有任何的I/O操作完成,阻塞时间超过timeout参数,则它返回-1,并将errno设置EAGAIN(不想设置时间限制,可以将timeout传入为NULL);
如果任何I/O操作完成,则它返回0;
如果在调用aio_suspend时,所有异步I/O以完成,则aio_suspend不阻塞直接返回。
参数list表示指向aiocb数组的指针,参数nent表示数组中的条目数量,除了空指针,其他条目必须指向初始化I/O操作的AIO控制块。
函数aio_cancel可以取消等待中的异步I/O操作。
1 |
|
aio_cancel返回值有:
参数fd指定了执行异步操作的文件描述符,如果aiocb设置为NULL,则系统尝试取消fd指向的文件上的所有异步操作。其他情况下,系统尝试取消单个异步操作。之所以描述为“尝试”,因为操作系统无法保证能成功取消正在进程中的异步操作。
aio_cancel操作成功,对相应的AIO控制块调用aio_error会返回错误ECANCELED。如果操作不成功,AIO控制块无变化。
函数lio_listio可以提交一系列有AIO控制块列表描述的I/O请求。
1 |
|
参数mode有:
参数list指向AIO控制块列表,指代所有要进行的I/O操作。
参数nent指定数组元素的个数,如果list为NULL,该参数被忽略。
引入POSIX异步操作I/O接口的目的是为了避免在执行I/O操作时阻塞进程。
下面使用异步I/O翻译一个文件
1 |
|
这里使用了8个缓冲区,同时最多可以有8个异步I/O操作处于等待状态。使用off偏移量,可以实现多个异步I/O同时进程翻译文件的不同位置。
readv和writev用于一次函数调用中读、写多个非连续的缓冲区,这两个函数也称为散布读、聚集写。
1 |
|
第一个参数fd是文件描述符;
第二个参数iov是一个指向iovec结构数组的指针,第三个参数iovcnt是数组的大小(最大为IOV_MAX),iovec结构如下:
1 | struct iovec { |
下图是iovec结构的描述:
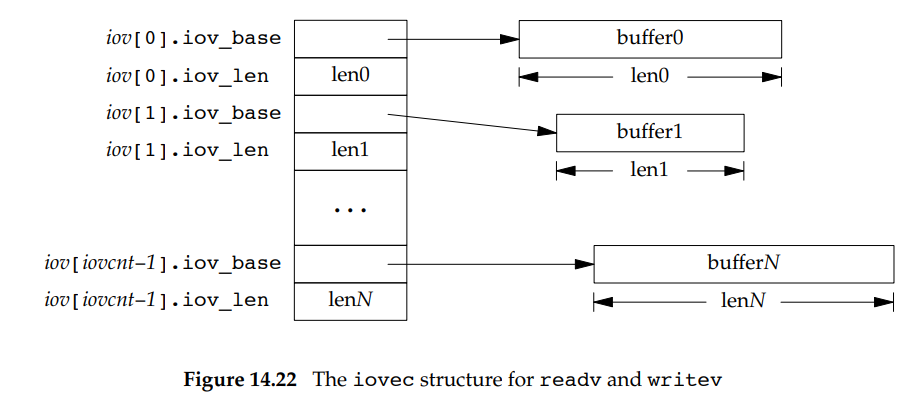
readv按上述顺序将读入的数据散布到各个缓冲区中,readv总是先填满一个缓冲区,在写入下个缓冲区。readv返回读的总字节数,如果是文件末尾,返回0。
writev按上述顺序从各个缓冲区中输出数据。writev返回输出的总字节数,通常为所谓缓冲区长度之和。
存储映射I/O将磁盘文件映射到一个缓冲区中,当从缓冲区中取数据,相当于从文件中读取相应字节数;当向缓冲区写数据,相应的字节会自动写入文件。这就可以不使用read和write的情况下I/O。
使用之前,要将给定的文件映射到一个存储区域中,该过程由mmap函数实现。
1 |
|
参数addr指定映射区域地址,通常设为0,表示由系统分配映射区域;参数fd指映射的文件,在映射之前,必须打开该文件;参数len为映射的字节数;off为映射字节在文件中的偏移位置;prot参数为映射存储区的保护要求,如下表所示:
| prot | 说明 |
|---|---|
| PROT_READ | 映射区可读 |
| PROT_WRITE | 映射区可写 |
| PROT_EXEC | 映射区可执行 |
| PROT_NONE | 映射区不可访问 |
prot可设为上述参数的任意组合的按位或。对映射区的保护要求不能超过文件open模式访问权限。例如文件open只读打开,那么prot不能设为PROT_WRITE。
flag通常有3中参数:
flag可能还有其他参数,但都是其他实现特有的。
函数mprotect可以更改一个现有映射的权限。
1 |
|
注意,此处的addr必须是系统页长(linux一般为4096)的整数倍。prot与mmap中的相同。
如果mmap的flag参数设为MAP_SHARED,那么修改不会立即写回到文件,写回的时机由内核的守护进程决定。而且,就算只修改了一页中的一个字节,修改也会将整个页写回。
如果共享映射的页已修改,可以调用msync将该页冲洗到被映射的文件中。该函数与fsync相似,但仅作用于映射区,fsync冲洗整个文件。
1 |
|
如果映射私有,则不修改映射的文件。与其他映射函数一样,addr必须是系统页长的整数倍。
flags有两个参数:
进程终止时,会自动解除存储映射区的映射,也可以调用munmap解除映射区。注意,关闭映射区对应的文件描述符并不解除映射区。
1 |
|
调用munmap不会将映射区的内容写到磁盘文件上。解除映射区后,对MAP_PRIVATE存储区的修改会被丢弃。
什么是守护进程?
守护进程通常在系统引导时启动,系统关闭时终止。它们不控制终端,在后台运行。
在我的Linux系统中输入:ps -axj,输出了以下参数:
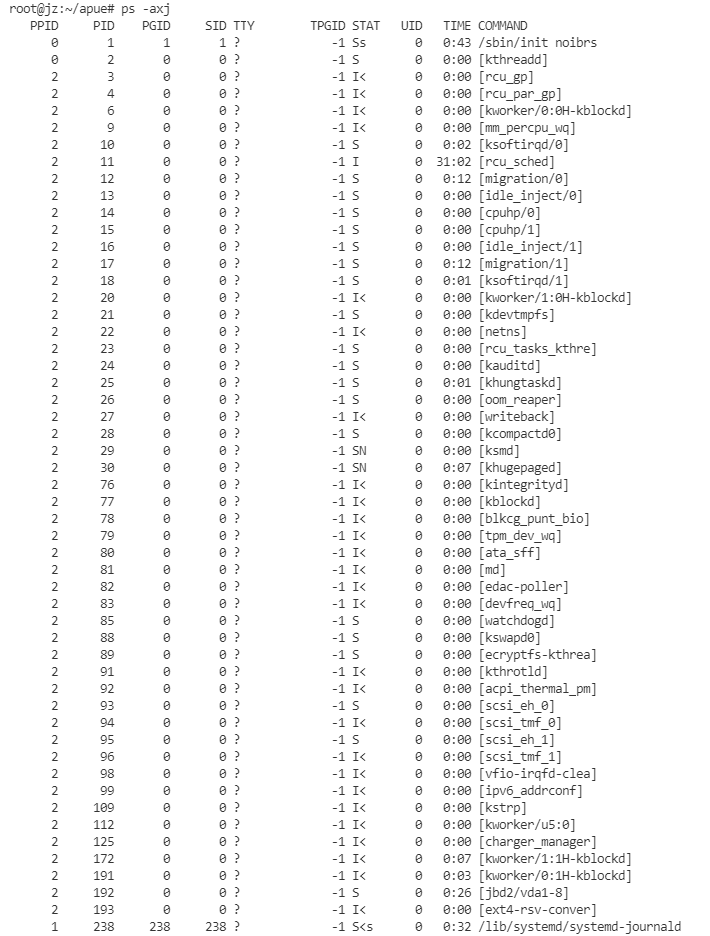
其中,PPID—父进程ID、PID—进程ID、PGID—进程组ID、SID—会话ID、UID—用户ID、TTY—终端名称、COMMAND—命令字符串。
父进程ID为0的进程是内核进程,内核进程存在于系统的整个生命期中,以超级用户特权运行,无命令行。
内核守护进程名字用[]中,Linux通过名为kthreadd的内核进程来创建其他内核进程,因此该进程是其他内核进程的父进程。在这些进程中,如:
大多数守护进程都以超级用户root特权运行(即UID是0),所有守护进程没有控制终端,TTY都是?。内核守护进程以无控制终端方式启动,用户层守护进程不控制终端可能是调用了setsid的结果。用户层守护进程的父进程都是init进程。
创建守护进程的编程规则:
下面是一个守护进程的初始化函数:
1 |
|
有些守护进程,在任一时刻必须只运行该守护进程的一个副本,防止一些操作的重复执行,可能导致出错。
文件和记录锁可以保证一个守护进程只有一个副本在运行。一个守护进程创建一个文件,并在文件上加了一把写锁,并且只允许创建一把写锁。此后创建写锁的操作均会失败,这告诉后续的守护进程此时已经有一个副本正在运行。在该守护进程终止时,写锁将自动被删除,从而去除了之前守护进程实例进行清理的相关操作。
下面是用文件和记录锁来保证只运行一个守护进程的一个副本。
1 |
|
本章主要介绍线程属性、同步原语属性、同一进程中的多个线程之间如何保持数据私有性、进程如何与线程进行交互。
下面是线程相关的一些限制:
| 限制名称 | 描述 | name参数 |
|---|---|---|
| PTHREAD_DESTRUCTOR_ITERATIONS | 线程退出时尝试销毁线程特定数据的最大次数 | _SC_THREAD_DESTRUCTOR_ITERATIONS |
| PTHREAD_KEYS_MAX | 进程可以创建的键的最大数目 | _SC_THREAD_KEYS_MAX |
| PTHREAD_STACK_MIN | 一个线程栈可用的最小字节数 | _SC_THREAD_STACK_MIN |
| PTHREAD_THREADS_MAX | 进程可以创建的最大线程数 | _SC_THREAD_THREADS_MAX |
下面描述了4种操作系统实现中线程限制的值,其中“没有确定限制”并不意味着值是无限的:
| 限制名称 | FreeBSD 8.0 | Linux 3.2.0 | Mac OS X 10.6.8 | Solaris 10 |
|---|---|---|---|---|
| PTHREAD_DESTRUCTOR_ITERATIONS | 4 | 4 | 4 | 没有确定限制 |
| PTHREAD_KEYS_MAX | 256 | 1024 | 512 | 没有确定限制 |
| PTHREAD_STACK_MIN | 2048 | 16384 | 8192 | 8192 |
| PTHREAD_THREADS_MAX | 没有确定限制 | 没有确定限制 | 没有确定限制 | 没有确定限制 |
pthread接口允许我们通过关联的不同属性来细调线程和同步对象的行为。管理这些属性的行为有:
在pthread_create函数中,有一个参数是pthread_attr_t,它可以修改线程默认属性。可以使用pthread_attr_init初始化pthread_attr_t结构。在调用pthread_attr_init后,pthread_attr_t结构所包含的就是操作系统实现支持的所有线程属性的默认值。
1 |
|
pthread_attr_init初始化的属性对象是动态分配的,所以需要pthread_attr_destroy来释放这些内存空间。
分离线程:如果在创建线程时就知道不需要了解线程的终止状态,就可以修改pthread_attr_t 结构中detachstate线程属性,让线程一开始就处于分离状态。detachstate具有两个合法值:PTHREAD_CREATE_DETACHED——以分离状态启动线程、PTHREAD_CREATE_JOINABLE——正常启动线程,应用程序可以获取线程的终止状态。
1 |
|
线程栈,即为线程分配的栈。可以使用pthread_attr_getstack和pthread_attr_setstack对线程栈属性进行管理。
1 |
|
对于线程,虚地址空间的大小是固定的。但对于线程,同样大小的虚地址空间必须被所有的线程共享。如果使用许多线程,则这些线程栈累计大小就超过了可用的虚地址空间,就需要减少默认的线程栈大小。如果线程的函数分配了大量的自动变量,或调用函数设计很深的栈,则需要的栈比默认的大。
如果线程栈的虚地址空间消耗完了,则需要使用malloc或mmap来为可替代栈跟配空间,并用pthread_attr_setstack函数来改变新建线程的栈位置。stackattr参数指向线程栈的最低可寻址地址,该地址与边界地址对齐。当然,stackattr不一定是站的开始地址,如果一个处理器栈从高地址向低地址增长,那么stackaddr是线程栈的结尾位置。
应用程序可以通过pthread_attr_getstacksize和pthread_attr_setstacksize读取或设置线程属性stacksize。
1 |
|
其中,设置stacksize时其大小不能小于PTHREAD_STACK_MIN。
线程属性guardsize控制线程末尾用以避免栈溢出的扩展内存大小,默认值由具体实现决定,一般为系统页大小。将guardsize设置为0,则不会提供警戒缓冲区。如果程序修改了线程属性stackaddr,则系统认为由我们自己管理栈,栈警戒缓冲区机制无效,等同于将guardsize设置为0。
1 |
|
如果guardsize被修改,操作系统可能把它取为页大小的整数倍。如果线程的栈指针溢出至警戒区域,应用程序就可能通过信号接收到出错信息。
more >><details>
<summary>标题1</summary>
<pre><code>代码内容
</code></pre>
</details>
效果如下:
代码内容
这里会有一个问题,当编写C程序,C程序中的头文件<>无法显示。
<details>
<summary>标题2</summary>
<pre><code>#include <stdio.h>
</code></pre>
</details>
问题的效果如下,可以看到<>中的内容消失:
#include
此时可以将代码块中的<替换为<、>替换为>,如下:
<details>
<summary>>标题3</summary>
<pre><code>#include <stdio.h>
</code></pre>
</details>
效果如下:
#include <stdio.h>
在程序设计时把进程设计成某个时刻,每个线程能够处理各自独立的任务。这有很多好处:
即使运行在单处理上,程序也可以通过多线程进行简化。而且,即使多线程程序在串行化任务时阻塞,由于某些线程在阻塞时还有其他线程可以运行,所以多线程程序在单处理上运行还是可以改善响应时间和吞吐量的。
每个线程都包含有表示执行环境所必须的信息,其中包括:线程ID、一组寄存器值、栈、调度优先级、策略、信号屏蔽字、errno变量(每个线程拥有属于自己的局部errno,以免一个线程干扰另一个线程)、线程私有数据。一个进程的所有信息对该进程的所有线程共享,包括可执行程序的代码、程序的全局内存、堆内存、栈、文件描述符。
每个线程都有各自的线程ID。进程ID是整个系统中唯一的,线程ID是它所属的进程下上文中才有意义。
线程ID是pthread_t数据类型表示,所有可移植操作系统不能把它作为整数处理,pthread_equal函数是用于对两个线程ID进行比较。
1 |
|
Linux3.2.0 使用无符号长整型(unsigned long int)表示pthread_t ;
Solaris 10 使用无符号整型(unsigned int)表示pthread_t;
FreeBSD 8.0和Mac OS X 10.6.8用一个指向pthread结构的指针表示pthread_t。
线程可以通过pthread_self函数获取自身线程ID。
1 |
|
当线程需要识别以线程ID为标识的数据结构时,pthread_self函数和pthread_equal可以一起使用。如:
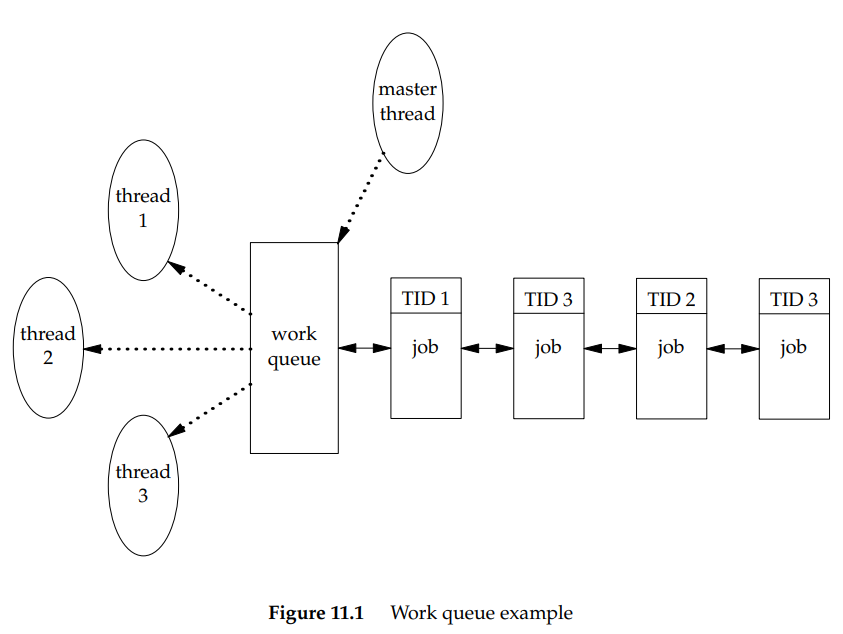
下图为主线程控制工作队列实例。可以看到,主线程可以将新作业放进工作队列中,另外3个线程组成的线程池从队列中移出作业,当然线程不能任意从队列顶端取出作业,而是由主线程控制作业分配,主线程会在每个待处理作业的结构中标志处理该作业的线程ID,每个工作线程只能移除有自己线程ID的作业。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true